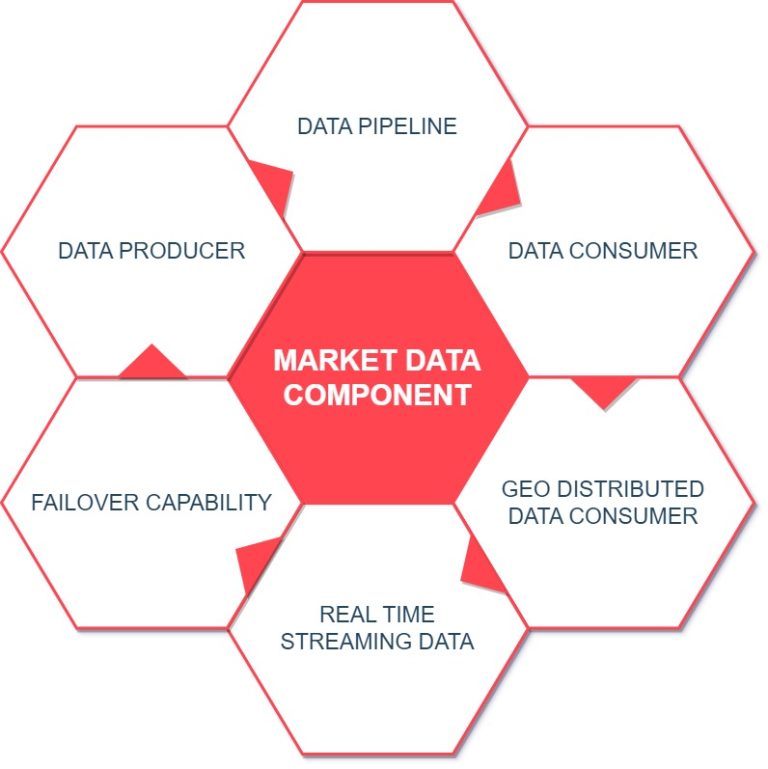
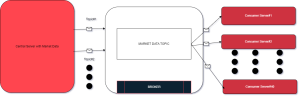
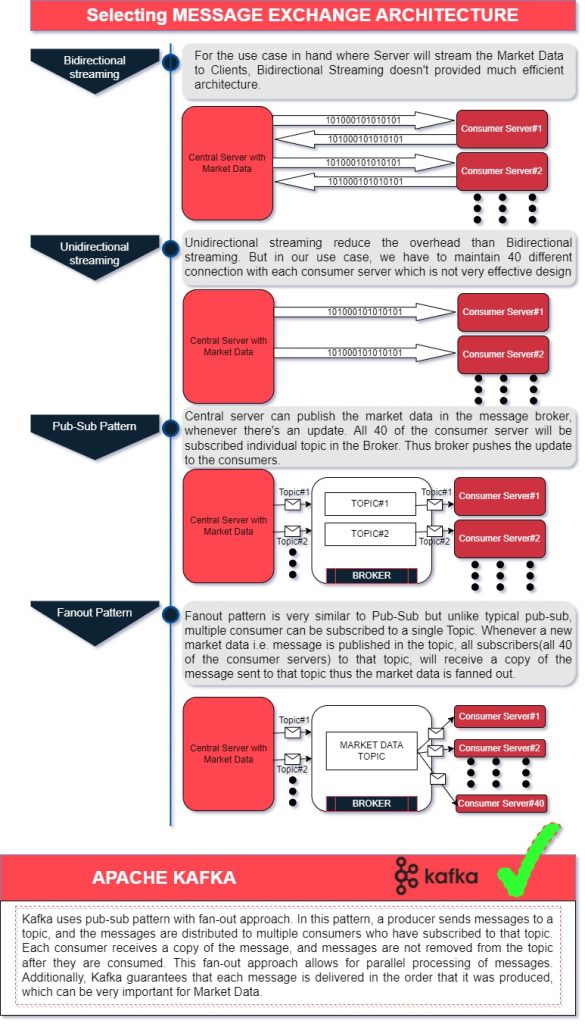
Let’s begin the design from the source . . . The Central Server where the Market Data is located.
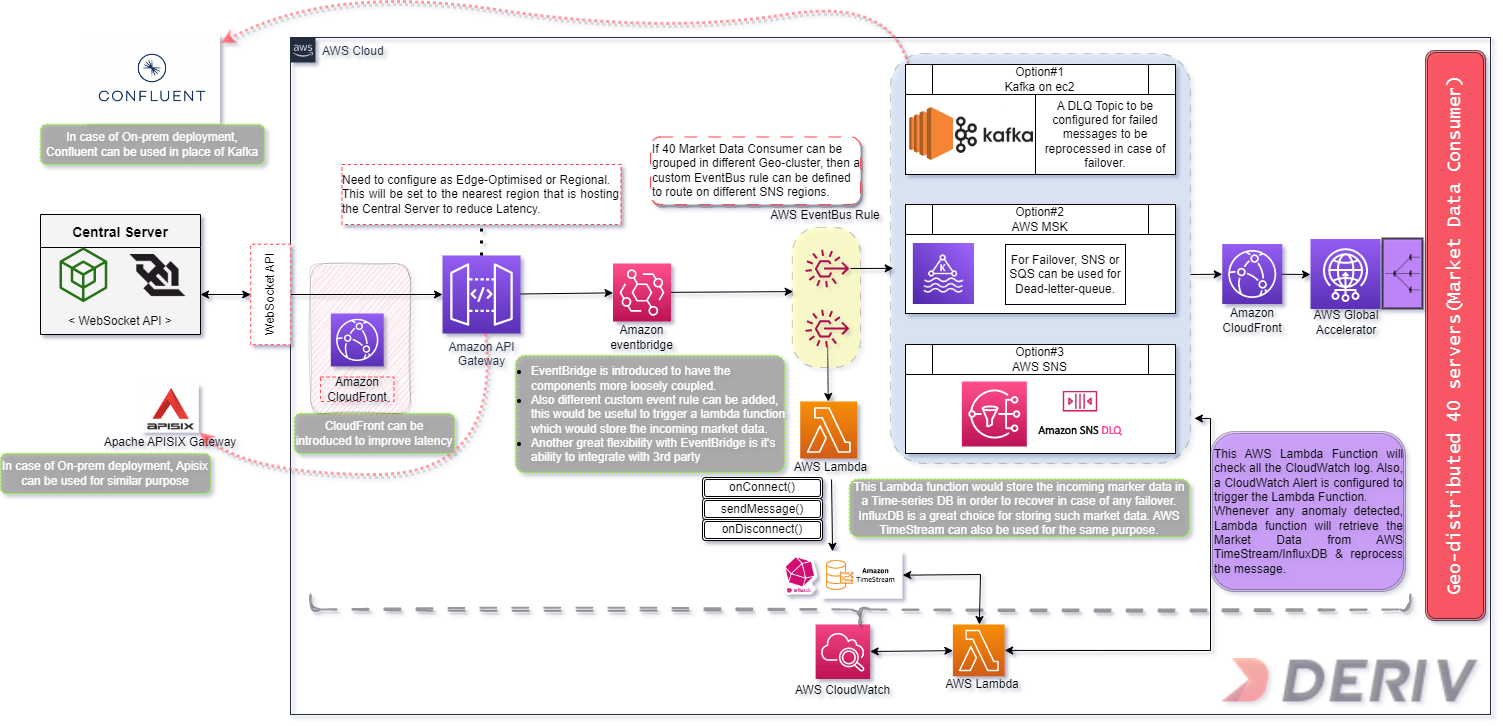
Now, previously we decided on using WebSocket protocol and also assumed that Deriv’s financial system is privy to WebSocket. So, this central server exposes the Market Data in a WebSocket API. This WebSocket API will be exposed to an API Gateway. If we go for On-prem private cloud deployment, then we can use Apache APISIX Gateway as the API Gateway. However, since the component is meant to use on a global scale, spanning across different geo-location, it doesn’t make much sense to go for an on-prem setup, unless there’s any specific use case. However, For this system design, I’d recommend going with AWS’s API Gateway.
While configuring the AWS API Gateway, Need to configure it as Edge-Optimized or Regional scope. This will be set to the nearest region that is hosting the Central Server to reduce latency on Market Data Ingest. AWS CloudFront can be introduced here as well, to reduce latency further.
Now, after much thought, I’ve decided to introduce AWS EventBridge to this system design. AWS API Gateway will pass the data stream to AWS EventBridge in the next hop. Reasons for using EventBridge are as follows:
- EventBridge is introduced to have the components more loosely coupled.
- Also, different custom event rules can be added, this would be useful to trigger a lambda function which would store the incoming market data.
- Another great flexibility with EventBridge is its ability to integrate with 3rd parties. If needed EventBridge can connect to other services outside AWS.
EventBridge also has an interesting capability to add custom EventBus Rule. For the next hop in my system design, one of the options is AWS SNS. Now, If the destinations (40 Market Data Consumers) can be grouped in different Geo-cluster, then a custom EventBus rule can be defined to route on different SNS regions. This could contribute to reducing latency as well.
Another EventBus Rule can be defined to pass the data to a custom AWS Lambda function. The purpose of this Lambda function is to keep track of all the messages passed through this data pipeline, in a permanent storage. This Lambda function would store the incoming marker data in a Time-series DB to recover in case of any failover.
InfluxDB is a great choice for storing such market data. AWS TimeStream can also be used for the same purpose.
Since we are using WebSocket APIs in AWS API Gateway, we can write our custom code at onConnect(), sendMessage() & onDisconnect() to store & track the market data passed through this Data Pipeline. This would be handy when we set up the monitoring for this system which I’ll explain a bit later. Kindly bear with me till then. 🙂
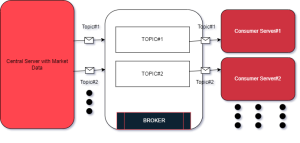
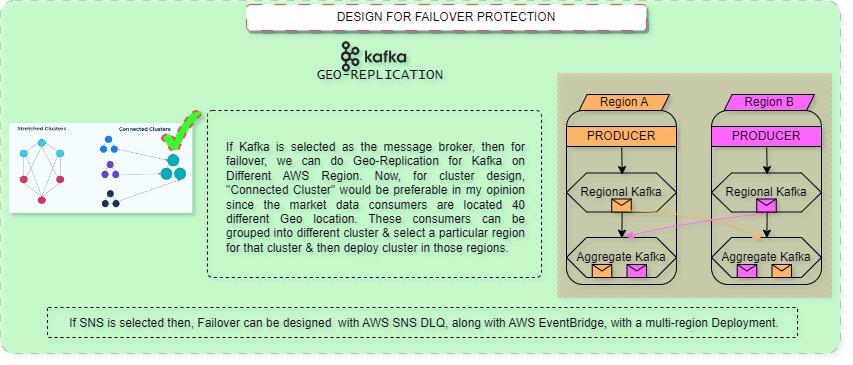
Now finally, to broadcast the market data to all 40 of the destination nodes, I’ve considered the below 3 options using AWS Services. However, If we consider a similar on-prem option to implement a similar system design, we can use Confluent, this is based on Kafka but they expanded on core Kafka capabilities. They have good support on Multi-geo replication for Kafka which can some very handy in our use case. Now coming back to AWS Services, we have 3 options:
Kafka on ec2:
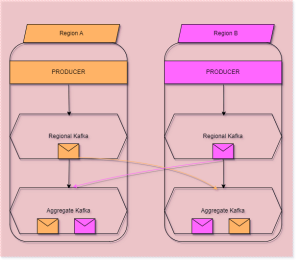
For option#1, We can consider deploying a Multi-geo replicated Kafka cluster(More on that in the Failover section below) which will be deployed in different geo-location. A DLQ(Dead-Letter-Queue) Topic is to be configured for failed messages to be reprocessed in case of failover. While this option gives us more flexibility & control over the message broker, this also introduced an operational management overhead.
AWS MSK:
Another option can be using AWS’s Managed Streaming for Apache Kafka and AWS MSK. MSK can securely stream data with a fully managed, highly available Apache Kafka service. For Failover, SNS or SQS can also be used for Dead-Letter-Queue.
AWS SNS:
Another great option here can be using AWS SNS. This can act as a single message bus that will deliver the market data to all 40 of the destination nodes. This is a fast & highly fault-tolerant service that can deliver with minimal latency & reliably. For failover, AWS SNS DLQ can be configured.
Last Mile Delivery:
Any of these 3 options mentioned above can be used for message broker service. Now, from either of these options, the next hop will be the last-mile Delivery.
Last-mile delivery of this component can be very tricky since all 40 of these consumers are geographically distributed across the globe. One of the biggest reasons to choose AWS is that it has great global support. AWS has a strong backbone private network which has great network latency & AWS offer to use their backbone for your data to stream through their backbone network for a reasonable charge. In my design, I’ve suggested using AWS Global Accelerator along with AWS CloudFront to leverage the best latency while using AWS’s backbone network structure so that our Market Data will stream through the AWS Backbone for last-mile delivery at 40 different consumer servers.
Monitoring:
For monitoring, first, we’ll enable AWS CloudWatch to capture all the logs of all the AWS services used designing in this component. We’ll introduce another Lambda function for monitoring. This AWS Lambda Function will check all the CloudWatch logs. Also, CloudWatch Alert will be configured to trigger the Lambda Function, in case any anomaly is detected. Both of these components will keep a close eye on the whole component. Whenever any anomaly is detected, the Lambda function will retrieve the Market Data from AWS TimeStream/InfluxDB & reprocess the message. I’ve already mentioned this earlier. The other Lambda function was deployed to keep track of the incoming market data stream & store it in a Time-Series DB. Now this monitoring lambda can leverage this incoming Market Data Stream stored in the TimeSeries DB for faster reprocessing. We can extend this Lambda function to re-submit the failed messages to the message broker topic for reprocessing.